Alte Aktenordner, neue Intelligenz: Industriedokumentation durchsuchbar machen
Veröffentlicht: 9. April 2026
Betriebsanleitungen aus den 90ern, handgezeichnete Schaltpläne, vergilbte Wartungsprotokolle — in vielen Industrieunternehmen schlummern Zehntausende Seiten technischer Dokumentation in Archivregalen. Wer eine bestimmte Zeichnungsnummer sucht oder wissen will, wann die Hydraulikpresse zuletzt gewartet wurde, blättert. Und blättert. Und blättert.
Wir haben uns gefragt: Was wäre, wenn man diese Dokumente einfach fragen könnte?
Die Herausforderung
Die Ausgangslage klingt überschaubar, hat es aber in sich:
- Gemischte Inhalte: Fließtext und technische Zeichnungen liegen oft im selben Stapel — manchmal sogar auf derselben Seite.
- Kein Standard: Manche Seiten sind OCR-freundliche Textdokumente, andere sind großformatige Schaltpläne, bei denen nur das Schriftfeld verwertbare Textinformationen enthält.
- Datensouveränität: Für unsere Zielgruppe — Industrieunternehmen mit sensiblen technischen Unterlagen — ist Cloud keine Option. Kein Byte darf das Kundennetzwerk verlassen.
Der Ansatz: Zwei Streams, eine Pipeline
Die zentrale Erkenntnis war, dass Textdokumente und technische Zeichnungen grundlegend unterschiedliche Verarbeitungswege brauchen. Daraus entstand eine Pipeline mit automatischer Vorklassifikation:
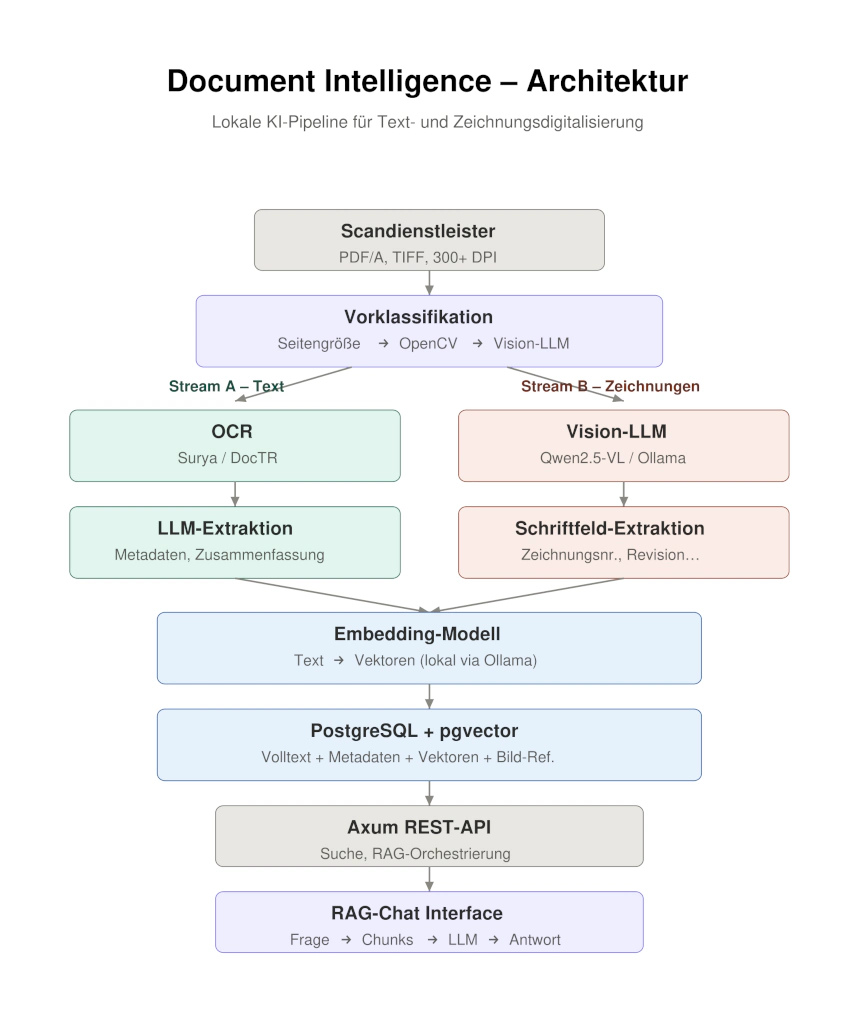
Eine Kaskade aus Bildgrößenanalyse, OpenCV-Heuristik und — im Zweifelsfall — einem Vision-LLM entscheidet für jede einzelne Seite: Text oder Zeichnung? Je nach Ergebnis nimmt die Seite einen anderen Weg:
- Stream A (Text): OCR extrahiert den Rohtext, ein LLM fasst zusammen und extrahiert Metadaten.
- Stream B (Zeichnung): Ein Vision-Modell liest das Schriftfeld direkt vom Bild — Zeichnungsnummer, Revision, Maßstab, alles was der Titelblock hergibt.
Am Ende münden beide Streams in dieselbe Vektordatenbank. Die Unterscheidung ist ab diesem Punkt irrelevant — Text und Zeichnungen sind gleichberechtigte Wissensquellen.
Die Architektur: Microservices im lokalen Netz
Die Pipeline besteht aus spezialisierten Services, die über REST kommunizieren und von einem zentralen Scheduler orchestriert werden:

Ein File-Watcher erkennt neue Scan-Stapel automatisch, legt Jobs in der Datenbank an, und der Scheduler arbeitet sie Seite für Seite ab. Kein Message-Broker, kein Kafka — die Job-Queue läuft direkt in PostgreSQL mit SELECT ... FOR UPDATE SKIP LOCKED. Pragmatisch und ausreichend.
Das Ergebnis: Fragen statt Blättern
Am Ende steht ein Chat-Interface, in dem Nutzer natürlichsprachliche Fragen stellen können — auf Deutsch, Englisch oder in jeder anderen Sprache, die das Embedding-Modell kennt. Die Antworten basieren auf den tatsächlich verarbeiteten Dokumenten, mit klickbaren Quellenangaben, die direkt zum Originalscan führen.
Die Kombination aus Vektorsuche und RAG sorgt dafür, dass nicht nur exakte Begriffe gefunden werden, sondern auch semantisch verwandte Inhalte — wer nach “Ölwechselintervall” sucht, findet auch Seiten, die von “Schmierstoffaustausch” sprechen.
Was wir dabei gelernt haben
Ein paar Erkenntnisse aus dem Entwicklungsprozess, die wir nicht verschweigen wollen:
- Vorklassifikation spart enorm viel Rechenzeit. Zeichnungen durch eine OCR-Engine zu jagen bringt nichts außer Rauschen. Die Heuristik davor ist simpel, aber wirkungsvoll.
- Vision-LLMs sind erstaunlich gut im Lesen von Schriftfeldern — selbst bei 30 Jahre alten, leicht schiefen Scans.
- Multilinguale Embeddings sind ein Gamechanger. Das gleiche Modell versteht deutsche Wartungsprotokolle und englische Datenblätter, und die Suche funktioniert sprachübergreifend.
- On-Premise heißt nicht zwangsläufig Kompromisse. Mit quantisierten Modellen und ONNX Runtime läuft die gesamte Pipeline auf einer einzigen Workstation mit Consumer-GPU.
Der Technologie-Stack
Die Pipeline besteht aus rund zehn containerisierten Services, orchestriert mit Podman. Die Kernkomponenten:
Dokumentenverarbeitung:
- OCR: PaddleOCR — mit Layout- und Tabellenerkennung
- Klassifikation: OpenCV-Heuristik (Hough-Linien + Textdichte) mit Vision-LLM-Fallback
- Vision- & Text-LLM: Qwen2.5-VL-7B (Q4_K_M) via Ollama — sowohl für Schriftfeld-Extraktion als auch für Metadaten-Generierung und RAG-Chat
- Embeddings: multilingual-e5-large (Microsoft) — ONNX Runtime, 1024 Dimensionen, über 100 Sprachen
Infrastruktur:
- Backend-Services in Rust (Axum, SQLx, Tokio) — Watcher, Scheduler, Classifier, Extractor, API-Server
- ML-Services in Python (FastAPI) — OCR und Embedder
- Frontend: Vue.js 3 + TypeScript, gebaut mit Vite, ausgeliefert über nginx
- Datenbank: PostgreSQL 17 mit pgvector für Vektor-Suche (Cosine-Similarity, IVFFlat-Indizes)
- Hardware: Linux-Workstation mit NVIDIA RTX 4070 (12 GB VRAM), Ollama läuft containerisiert mit GPU-Passthrough
Kein Message-Broker, keine externen APIs, kein Byte verlässt das Netzwerk. Die Job-Queue läuft direkt in PostgreSQL mit SELECT ... FOR UPDATE SKIP LOCKED — pragmatisch und für den Durchsatz völlig ausreichend.
Wie es weitergeht
Das System läuft, die ersten Stapel sind verarbeitet. Aber es gibt noch viel Potenzial:
- Dokumentengruppierung: Automatisches Erkennen, welche Seiten innerhalb eines Stapels logisch zusammengehören — ein Stapel ist nicht immer ein Dokument.
- Chunk-basierte Embeddings: Längere Texte in semantisch sinnvolle Abschnitte zerlegen für präzisere Suchtreffer.
- Feedback-Loop: Nutzer-Korrekturen an der Klassifikation zurück in die Pipeline fließen lassen.
Die größte Erkenntnis: Das schwierigste Problem war nicht die KI. Es war, zuverlässig zwischen einer Betriebsanleitung und einem Schaltplan zu unterscheiden — und das in unter einer Sekunde, ohne Cloud, auf einer RTX 4070.
Dieser Artikel beschreibt ein laufendes Projekt. Der Technologie-Stack und die Architekturentscheidungen können sich im weiteren Verlauf ändern.
Weitere Posts